What is a Neural Network?
Neural networks are the backbone of modern artificial intelligence (AI). They have evolved from simple, biologically inspired models to complex, machine-driven systems capable of performing tasks that were once considered the sole domain of human intelligence. But what exactly is a neural network, and how did it come into existence?
The Origins: A Biological Blueprint
The story of neural networks begins with the human brain, a remarkable organ composed of billions of neurons. These neurons communicate through electrical signals, forming intricate networks that allow us to think, learn, and perform complex tasks.
In the 1940s, early AI pioneers began drawing inspiration from this biological structure to design computational models capable of mimicking human learning. In 1943, Warren McCulloch and Walter Pitts introduced the first artificial neural network model. Their work was based on the idea that neurons fire in response to inputs, a fundamental principle of how the brain processes information. However, the lack of computational power at the time posed significant challenges to further advancements.
Why was the early development of neural networks limited by computational power?
The Perceptron: The Dawn of Machine Learning
In the late 1950s, Frank Rosenblatt, an American psychologist, introduced the Perceptron—a single-layer neural network designed to perform binary classification tasks. The Perceptron could learn from labelled data by adjusting weights to improve its predictions over time. This was a significant milestone, as it marked the first time that machines could learn from experience.
However, despite its promise, the Perceptron had limitations. It struggled with complex problems, particularly those requiring non-linear separability, such as image recognition. This shortcoming led to a period of disillusionment known as the AI Winter, during which funding and interest in neural networks declined.
What made the Perceptron a breakthrough in AI?
Why did the Perceptron fail to solve more complex tasks?
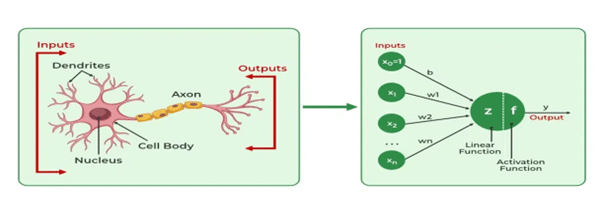
The Rise of Multi-Layer Perceptron (MLPs)
The introduction of multi-layer perceptron (MLPs) in the 1980s was a breakthrough in neural network history. By stacking multiple perceptron layers, researchers could solve more complex problems. The addition of hidden layers introduced non-linearity, allowing neural networks to approximate any function. However, training deeper networks became challenging due to the vanishing gradient problem.
Structure of an MLP (Diagram Description)
- Input Layer: Represents input features.
- Hidden Layers: Introduces non-linearity using activation functions like sigmoid, ReLU, or tanh.
- Output Layer: Provides predictions or classifications.
🔹 How do hidden layers improve neural networks?
🔹 What is the vanishing gradient problem, and how does it affect training?

Implementing Multi-Layer Perceptron using TensorFlow on the MNIST Data set
## Importing necessary modules
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Normalize image pixel values by dividing by 255 (grayscale)
gray_scale = 255
x_train = x_train.astype(‘float32’) / gray_scale
x_test = x_test.astype(‘float32’) / gray_scale
# Visualizing 100 images from the training data
fig, ax = plt.subplots(10, 10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28, 28), aspect=’auto’)
k += 1
plt.show()
# Building the Sequential neural network model
model = Sequential([
# Flatten input from 28×28 images to 784 (28*28) vector
Flatten(input_shape=(28, 28)),
# Dense layer 1 (256 neurons)
Dense(256, activation=’sigmoid’),
# Dense layer 2 (128 neurons)
Dense(128, activation=’sigmoid’),
# Output layer (10 classes)
Dense(10, activation=’softmax’),
])
# Compiling the model
model.compile(optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
# Training the model with training data
model.fit(x_train, y_train, epochs=10,
batch_size=2000,
validation_split=0.2)
# Evaluating the model on test data
results = model.evaluate(x_test, y_test, verbose=0)
print(‘Test loss, Test accuracy:’, results)
Activation Functions in Neural Networks
Activation functions are integral components of neural networks (NN) that enable them to learn complex patterns in data. Without activation functions, neural networks would be restricted to modelling only linear relationships between inputs and outputs.
1. Sigmoid Activation Function
The sigmoid activation function is one of the most historically important functions in the development of neural networks. It is mathematically represented as:
f(x)=f(x)=
1/(1+e−x)1/(1+e−x)
This function takes a real-valued input and squashes it to a value between 0 and 1. The sigmoid curve has an “S”-shape and asymptotes to 0 for large negative values and 1 for large positive values. This characteristic makes the sigmoid useful in binary classification problems, where the output can be interpreted as a probability.
2. Tanh (Hyperbolic Tangent) Activation:
The tanh activation function is defined as:
f(x)=f(x)=
(ex−e−x)/(ex+e−x)(ex−e−x)/(ex+e−x)
The tanh function outputs values in the range of -1 to +1. This means that it can deal with negative values more effectively than the sigmoid function, which has a range of 0 to 1.
Why might tanh be preferred over sigmoid in certain cases?
3. ReLU (Rectified Linear Unit) Activation:
The ReLU activation function has the form:
f(x)=max(0,1)f(x)=max(0,1)
It thresholds the input at zero, returning 0 for negative values and the input itself for positive values.
Since ReLU outputs zero for all negative inputs, it naturally leads to sparse activations; at any time, only a subset of neurons is activated, leading to more efficient computation.
How does ReLU help mitigate the vanishing gradient problem in deep networks?
Revolutionizing Learning: Backpropagation and the Rise of Deep Learning
The breakthrough that revived interest in neural networks came in the 1980s with the development of backpropagation a learning algorithm that allowed multi-layer networks to adjust weights more efficiently.
Backpropagation made it possible to train deeper networks with multiple layers, paving the way for more powerful models that could tackle increasingly complex problems. With backpropagation, neural networks could now learn from vast amounts of data, improving their accuracy in tasks like speech recognition, natural language processing, and image classification. These advancements led to the emergence of deep learning, a subset of machine learning that uses neural networks with many layers to model intricate relationships in data. Deep learning became the driving force behind many AI applications, from virtual assistants like Siri and Alexa to self-driving cars and medical diagnostic tools.
Backpropagation: Weight Update Rule
Backpropagation is the fundamental algorithm used to train deep neural networks by adjusting weights based on the gradient of the loss function.
w(t+1)=w(t)−η∂L∂twt+1=wt−𝜂𝜕L𝜕t
Where:
- w(t)wt is the weight at the current step.
- η is the learning rate.
- ∂L∂t𝜕L𝜕t is the gradient of the loss function with respect to the weight.
- w(t+1)wt+1is the updated weight after applying the gradient descent step.
Questions to Consider:
- How did backpropagation improve the efficiency of training neural networks?
- What are some real-world applications where deep learning has made a significant impact?
Here is a simple illustration of how backpropagation works by adjusting weights:
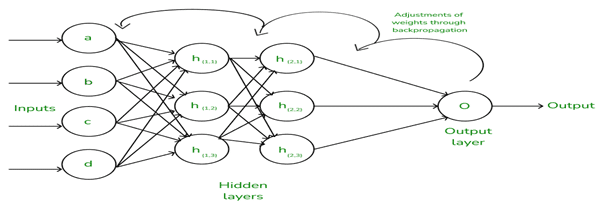
Deep Learning Becomes a Reality
In 1989, deep learning became an actuality when Yann LeCun, et al., experimented with the standard backpropagation algorithm (created in 1970), applying it to a neural network. Their goal was to train the computer to recognize handwritten ZIP codes on mailed envelopes. This new system worked, and as a result, deep learning was born. Deep learning is a subdivision of machine learning and uses algorithms to process data as it attempts to imitate the human thinking process. Layers of algorithms are used to:
- Process data
- Understand human speech
- Visually recognize objects
- Perform time-series analysis
- Diagnose medical issues
Questions to Consider:
- How did Yann LeCun’s work in 1989 contribute to the rise of deep learning?
- What are some real-world applications of deep learning in industries today?
The Role of Big Data and GPUs
As neural networks grew more sophisticated, they required vast amounts of data and computational power to train effectively. This challenge was met with the rise of big data—massive datasets that could fuel machine learning algorithms—and Graphics Processing Units (GPUs), which accelerated the training process. GPUs, originally designed for rendering graphics in video games, proved to be incredibly efficient at handling the parallel computations required by neural networks, allowing them to process large datasets much faster than traditional CPUs. With these advancements, deep learning models became more accurate, scalable, and practical for a wide range of applications. Companies like Google, Facebook, and Tesla began leveraging neural networks to enhance their services, pushing the boundaries of AI.
Questions to Consider:
- How did GPUs revolutionize the way neural networks are trained?
- Why is big data critical for the success of deep learning models?
Big Data in AI
Big Data refers to massive datasets that are too large and complex to be processed by traditional methods. These datasets are often used to train deep learning models, enabling them to identify patterns and make predictions. For example, AI applications in natural language processing (like GPT models) require terabytes of text data, while computer vision tasks rely on millions of labelled images.
Techniques like distributed data processing using frameworks such as Apache Spark or Hadoop allow parallel data handling, ensuring scalability and efficiency.
Here’s an example of loading and processing a large dataset using PySpark:
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName(“Big Data Example”).getOrCreate()
# Load a large dataset
data = spark.read.csv(“large_dataset.csv”, header=True, inferSchema=True)
# Perform data processing
processed_data = data.filter(data[‘column’] > 10).groupBy(“category”).count()
processed_data.show()
Graphics Processing Units (GPUs) and Their Role in Deep Learning
Graphics Processing Units (GPUs) are specialized hardware designed to perform parallel computations. Neural networks involve matrix multiplications and other operations that benefit from this parallelism, making GPUs ideal for training deep learning models. Compared to CPUs, GPUs significantly reduce the time required to train models, especially for large datasets.
Questions to Consider:
- How do GPUs differ from CPUs in terms of performance for deep learning tasks?
- Why is parallelism important when training neural networks?
Using GPUs with PyTorch
A common library for GPU acceleration in Python is PyTorch. It allows seamless integration of GPUs for faster model training. Here’s an example of utilizing a GPU to train a neural network:
import torch
import torch.nn as nn
import torch.optim as optim
# Check if GPU is available
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
# Define a simple neural network
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# Create the model and move it to GPU
model = SimpleNet().to(device)
# Define loss and optimizer
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Dummy input data (moved to GPU)
inputs = torch.randn(100, 10).to(device)
targets = torch.randn(100, 1).to(device)
# Training loop
for epoch in range(10):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
print(f”Epoch [{epoch+1}/10], Loss: {loss.item()}”)
Together, Big Data and GPUs enable the creation of AI models that were once computationally infeasible. Companies leverage this combination to train massive models like GPT-4, which involves billions of parameters and datasets spanning terabytes
Neural Networks in the Modern Age
Neural networks have become integral to solving complex problems in fields ranging from healthcare and finance to autonomous systems and natural language processing. Modern advancements, including novel architectures, large-scale datasets, and cutting-edge hardware, have made neural networks highly efficient and capable of surpassing human-level performance in many tasks.
Questions to Consider:
- In what ways have neural networks evolved in recent years to tackle more complex problems?
- How do modern advancements like large datasets and powerful hardware contribute to the success of neural networks?
Key Architectures Driving Modern Neural Networks
Convolutional Neural Networks (CNNs):
- Primarily used in computer vision tasks like image classification, object detection, and facial recognition.
- CNNs process data with spatial hierarchies, making them highly effective for image-based problems.
Questions to Consider:
- Why are CNNs particularly well-suited for image-related tasks?
- How do spatial hierarchies in CNNs enhance the accuracy of image recognition?
Recurrent Neural Networks (RNNs) and LSTMs:
- Ideal for sequential data like time-series analysis, speech recognition, and natural language processing.
- LSTMs solve the vanishing gradient problem inherent in traditional RNNs, allowing for long-term memory.
Questions to Consider:
- What makes LSTMs more effective than traditional RNNs for tasks involving long-term dependencies?
- How do RNNs and LSTMs contribute to advancements in natural language processing?
Example: Text Generation Using LSTMs in TensorFlow
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.LSTM(128, input_shape=(100, 50)), # 100 time steps, 50 features
tf.keras.layers.Dense(1, activation=’sigmoid’)
])
model.compile(optimizer=’adam’, loss=’binary_crossentropy’, metrics=[‘accuracy’])
model.summary()
Transformers and Attention Mechanisms
Introduced in the “Attention Is All You Need” paper, transformers revolutionized language processing by enabling models like BERT and GPT.
Transformers process input sequences in parallel rather than sequentially, improving performance and scalability.
Example: Hugging Face’s Transformers library for text classification:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained(“bert-base-uncased”)
model = AutoModelForSequenceClassification.from_pretrained(“bert-base-uncased”)
inputs = tokenizer(“This is a great example of neural networks in modern AI!”, return_tensors=”pt”)
outputs = model(**inputs)
print(outputs.logits)
Impact and Future Directions
Modern neural networks are not only solving today’s challenges but are also pushing the boundaries of what machines can achieve. Technologies like zero-shot learning, multimodal AI (e.g., combining text and image understanding), and reinforcement learning will drive future advancements. Tools like PyTorch, TensorFlow, and Hugging Face ensure that developers and researchers can continue building innovative solutions.
Questions to Consider:
- How will zero-shot learning change the way models interact with unseen data?
- In what ways can multimodal AI be applied to real-world scenarios, such as autonomous vehicles or healthcare?
Ethical Considerations and Challenges in Neural Networks
The widespread use of neural networks raises ethical concerns and challenges, particularly in areas like data privacy, bias, and accountability.
Bias in Neural Networks: Models trained on biased datasets often perpetuate and even amplify these biases. For instance, facial recognition systems have shown higher error rates for certain demographic groups due to unbalanced training data.
Data Privacy: Training models on sensitive user data, such as medical or financial information, can lead to privacy violations if proper safeguards are not in place.
Explainability and Accountability: Deep learning models, especially those with millions of parameters, are often considered “black boxes,” making it difficult to understand their decision-making processes. This lack of transparency can hinder trust and adoption in critical sectors like healthcare or legal systems.
Questions to Consider:
- How can we reduce bias in neural network models, especially in critical applications like facial recognition or hiring algorithms?
- What are the best practices for safeguarding data privacy when training deep learning models on sensitive data?
- How can we improve the explainability of neural networks to foster trust in their decisions, particularly in high-stakes fields like healthcare?
The Future of Neural Networks: Opportunities and Innovations
As neural networks evolve, they are poised to revolutionize numerous domains further:
Neuro-Symbolic AI: Combining the symbolic reasoning of traditional AI with the pattern recognition capabilities of neural networks offers the promise of more interpretable and robust systems.
Quantum Neural Networks: Leveraging quantum computing to accelerate neural network training and computation could redefine what’s achievable, particularly in optimization and large-scale data problems.
Personalized AI: Neural networks are increasingly enabling tailored solutions, from personalized learning in education to customized treatments in precision medicine.
AI and Creativity: Generative models are pushing boundaries in art, music, and design, creating human-like outputs that were previously unimaginable.
The possibilities are vast, and the intersection of neural networks with emerging technologies like edge computing and 6G will unlock applications we can only begin to imagine today.
Conclusion
Neural networks have transformed from a theoretical concept inspired by the human brain into a cornerstone of modern AI, driving advancements across industries. From their early beginnings with the perceptron to the current era of deep learning and transformers, neural networks have consistently redefined the limits of technology.
However, as their influence grows, so do the responsibilities of researchers, developers, and organizations to address challenges related to ethics, transparency, and inclusivity. By combining innovative techniques, computational power, and a commitment to responsible AI, neural networks will continue to shape a future where machines not only learn but also contribute to solving humanity’s most pressing problems.