We’ve spent the past 2 decades up until the Data Cloud advent in building or plumbing infrastructure components.
After the evolution of Data Platforms in the state that we see i.e., platforms like Snowflake, Databricks being adopted widely, one thing is clear. Unless you are working on Uber or Airbnb scale, the wiser choice is to use managed services and focus on business value.
Now the tooling around the data ecosystem is ever growing and every week we see a new tool or platform pop up. To sum it up, a picture says thousand words…

Too many choices also lead to too much confusion, and eventually…
We are nothing but product of our choices.
AWS with its host of end-to-end services can come to rescue here and save you from analysis paralysis. Below is a sample architecture for batch data:
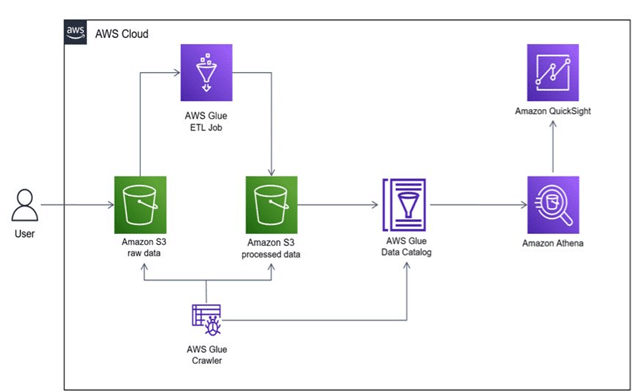
But why would you care about AWS at all?
There is good chance that you already use AWS services for other things, or you are considering on-prem to cloud migration for scalability of your data centre.
Let’s talk about the picture above.
After looking closely, we find AWS Glue product suite has evolved from what it used to be and is offering a multitude of capabilities under its umbrella. In this example, Batch pipeline as well as AWS Glue are both playing a crucial role.
Data Lake is not a new concept. In fact, AWS S3 is among the preferred storage services in public cloud space just because of its simplicity, scalability, and security. Combine that with Lake formation for data governance and you get the ability to secure your data with granular access control. This gives us a governance capability for all our data in AWS.
Athena and Quicksight provide ad-hoc query capabilities and reporting over data sitting in S3.
Now there are purpose build services as well, like DynamoDB, Redshift, Redshit Spectrum, OpenSearch, and others. And they do integrate well within overall AWS ecosystem, but we are focusing on the ones which cover maximum use cases.
A template to store data in S3 data lake would look something like this:

Data Lake Layers
All 3 steps can be done with AWS Glue without managing any of the infrastructure. It is, by design, a serverless ETL/ELT system and essentially a Data Integration service.
From ingesting raw data from on-premises data centre in AWS S3, to processing raw data and schematization of unstructured data and cataloguing it for systematic aggregation, query and reporting, AWS Glue handles the job seamlessly. At the heart of it, the Glue service uses Apache Spark under the hood, which comes along with AWS EMR serverless Spark. It also comes with another set of service for EDA called AWS Glue Databrew.
Combining all of the above, we can build an end-to-end data pipeline with AWS managed services. We can now focus on the business value that can be driven from data instead of managing the infrastructure or plumbing the tools together.
Hope this article helps in understanding how AWS can help with its Data Services.